
If your SaaS relies heavily on third-party AI like GPT-4 or Claude, and your product mainly acts as a simple interface for these tools, you might be running what’s called an AI “wrapper.” These thin layers of software often fail because they lack unique value, are easy to replicate, and depend entirely on external APIs. Worse, they’re vulnerable to platform updates that can render them irrelevant overnight.
Here’s the reality:
- 80-95% of AI wrapper startups fail to generate revenue in their first year.
- 966 U.S. startups shut down in 2024 alone, largely due to weak business models.
- 90% of AI startups are predicted to fail by 2026 because they can’t stand out or sustain long-term value.
The solution? Build a data moat - a competitive edge through proprietary datasets, deeper workflow integration, and advanced AI capabilities. This approach increases switching costs for users, protects your product from being easily replaced, and positions your business for higher margins and enterprise deals.
Key takeaways:
- Thin AI wrappers are unsustainable as competition grows and API providers absorb their features.
- Proprietary data, advanced AI, and workflow integration are essential to creating a durable business.
- Companies with strong data moats see higher valuations, better retention, and long-term resilience.
To future-proof your SaaS, focus on owning unique data, embedding your product into customer workflows, and developing AI capabilities that competitors can’t easily replicate. Without these, you risk becoming just another feature in someone else’s platform.
What Are AI Wrappers and Why Do They Fail?
What Counts as an AI Wrapper
To understand why AI wrappers often fall short, it's important to first define what they are. An AI wrapper is essentially a simple software layer that handles inputs, outputs, and interfaces for foundation models like GPT-4 or Claude. However, it doesn’t contribute anything unique - no proprietary data, custom logic, or distinct features[1][10]. Think of it as "prompt engineering wrapped in a user-friendly interface"[8]. In essence, you're just dressing up someone else’s intelligence with a polished look.
Here’s what makes a product a wrapper: it follows a straightforward Input → API Call → Output process. There’s no complex orchestration, recursive adjustments, or adaptive memory involved[5]. The product’s job is to send your query to OpenAI (or a similar provider), retrieve the response, and display it. That’s the whole cycle.
If replacing the OpenAI API with an open-source option like Llama would erase your product’s competitive edge, then it’s safe to say your product is just a wrapper[7]. In this case, your value lies entirely in someone else’s infrastructure - not in anything you’ve created or own.
Why Thin AI Layers Don't Work
Now that we know what an AI wrapper is, let’s explore why these thin layers often fail to succeed in the market. The core issue is what experts call the "Intelligence Paradox": as foundation models like GPT-4, Claude, or Gemini grow more advanced, the value of adding a simple user interface on top of them keeps shrinking[7]. The difference between what users can do for free with ChatGPT and what they’re asked to pay $20-$30 a month for in your wrapper becomes harder to justify.
The problem gets worse when model providers absorb key wrapper features into their own platforms - a phenomenon known as "Sherlocking"[1][2]. For example, one founder of a "Chat with PDF" tool saw their traffic plummet by 90% in a single weekend after OpenAI introduced a comparable feature for free to ChatGPT Plus users[7]. A single platform update can wipe out your entire business.
Another challenge is how easy it is for others to replicate a wrapper. A skilled developer can recreate most wrapper-based products in just a weekend[3], leaving you with no switching costs and no defensible advantage. Users can easily move to a competitor offering a better design or a cheaper price - because the real intelligence lies in the foundation model, not in your product.
sbb-itb-9cd970bThe AI Startup Trap: Why 99% of GPT Wrappers Fail (and the Playbook to Beat the Odds)
Why Thin AI Layers Collapse in Competitive Markets
The challenges in this space highlight why having a strong and exclusive data advantage is crucial for survival. Without such leverage, thin AI wrappers face growing pressures that often lead to their downfall.
Market Commoditization and Zero Switching Costs
The AI wrapper market is oversaturated. In 2024 alone, between 10,000 and 12,000 new AI startups emerged[11], with about 95% of them creating easily replicable, thin layers[11]. These wrappers often perform the same basic tasks: sending prompts to an API, processing the response, and presenting it to users. With so many products offering nearly identical functionality, standing out becomes extremely difficult.
On top of that, users can switch between these tools with almost no effort or cost[11]. Since most wrappers depend on the same APIs and lack unique data or deep integration into workflows, there’s little reason for customers to stay loyal. Even a slightly better user interface or a small price cut can cause users to jump ship.
As competition intensifies, the economic weaknesses of thin AI wrappers become even more pronounced.
The Pricing Race to the Bottom
Unlike traditional SaaS companies, which benefit from minimal costs as they scale, AI wrappers face ongoing expenses for every user interaction - commonly referred to as the "inference tax"[12]. While SaaS businesses often achieve gross margins of 80-90%, AI wrappers typically operate with margins of only 25-60%[12][11]. For every $100 earned, wrappers might spend $20-30 on API usage and another $25-35 on sales and marketing[12].
The situation worsens as large language model providers continue to slash their prices. Inference costs are dropping at a median rate of 50 times annually[11], allowing competitors to quickly lower their prices as well. This forces wrappers to accept lower rates, and any sudden increase in API costs or usage can wipe out already slim margins[12][6].
The financial realities are stark: 60-70% of AI wrappers make no revenue at all, and only 3-5% generate over $10,000 in monthly recurring revenue[12]. Meanwhile, customer acquisition costs for SaaS companies rose 22% between 2022 and 2023, with businesses now spending $1.61 to gain just $1 in annual recurring revenue[11]. Combined with high churn rates and thin profit margins, this creates a recipe for financial instability.
These economic pressures are already leading to widespread failures in the industry.
Real Examples of Failed AI Wrappers
The collapse of thin AI wrappers is happening right now. In 2024, 966 startups in the U.S. shut down - a 25.6% increase compared to the previous year[8]. Investor confidence has also taken a hit, with the percentage of venture capitalists viewing AI startups as "investable" dropping from 75% to 40% in just a few months during 2023[8].
The outlook is grim: 90% of AI startups are expected to fail by 2026, a failure rate 4.5 times higher than that of other industries[11][12]. OpenAI’s CEO, Sam Altman, captured this harsh reality when he warned founders, "We're just going to steamroll you"[11]. This sentiment is echoed in the industry, where OpenAI’s feature announcements are now referred to as "The Extinction Event"[7], signaling how a single update can obliterate entire categories of startups.
How to Build a Defensible Data Moat
Now that we've explored the pitfalls of relying on thin AI layers, let’s dive into crafting a real competitive edge. The secret? Building something that competitors can’t easily replicate. This means focusing on proprietary data, advanced AI capabilities, and deep workflow integration - a combination that makes it tough for customers to switch.
Use Proprietary Datasets
The foundation of a strong data moat is unique, structured user data - not data that’s scraped or bought. For example, Tesla has collected over 5 billion miles of real-world driving data to train its autonomous systems[13]. That’s the kind of proprietary dataset that no competitor can easily match.
A strong data flywheel drives continuous model improvements through user interactions. But not all data is equally valuable. Unstructured logs don’t offer much competitive edge. What you need is structured, cleaned data that’s ready for model training[14]. Behavioral data is particularly powerful - it reveals how users interact with your system, what they accept or reject, and how they correct your AI’s mistakes[18].
To build this kind of dataset, design your product to automatically capture user interaction data. Reinforcement Learning from Human Feedback (RLHF) can be integrated into your interface so that every user action - whether they accept or reject an AI suggestion - helps your model learn their preferences, like their brand voice or technical requirements[7][18]. Partnering with legacy industries, like manufacturers or biotech companies, can also give you access to decades of untapped, unstructured data[17].
Companies with real-time user interaction data can maintain a competitive edge for five years or more. On the other hand, businesses relying on static datasets might find themselves vulnerable within just 12-18 months[15].
"Data is no longer scarce. Signal is." - Alex Pawlowski, The Strategy Stack[18]
Add Advanced AI Capabilities
Once you’ve got proprietary data, the next step is to push beyond basic AI implementations. This means integrating vertical-specific unstructured data and creating feedback loops that enable your AI to take end-to-end actions. Retrieval-Augmented Generation (RAG) is a great example. It connects your AI to unique, domain-specific data - like weather patterns for logistics or historical labor costs for construction. This creates a "vertical context" that generic models like ChatGPT can’t match[7].
Abridge, for instance, integrated its AI into major electronic health record (EHR) systems like Epic in 2025, slashing doctors’ documentation time by 86%[19].
To test whether your product has a true competitive edge, try "The Swap Test." Ask yourself: If you replaced the OpenAI API with an open-source model, would your product still stand out?[7] If the answer is no, you’re likely still just a wrapper.
These advanced capabilities lay the groundwork for deeper customer engagement through workflow integration.
Create Workflow Lock-In
The final piece of the puzzle is embedding your AI deeply into your customers’ core processes. The goal is to make replacing your solution so complex that it requires a major overhaul of their workflows. This might involve tasks like adjusting cash flow forecasts or managing shipment holds[7][9].
Take Harvey AI as an example. By integrating directly into tools like Microsoft Word, Outlook, and iManage (a document management system used by 80 of the Am Law 100), Harvey AI achieved a 28% penetration rate among top law firms. This deep integration fueled 4x year-over-year growth in weekly active users[19]. Similarly, Glean reached a 93% adoption rate within organizations by leveraging a proprietary "Enterprise Graph" to map relationships between people and content[19].
Creating multi-player network effects can also strengthen your moat. When your tool requires collaboration between different roles - like designers, PMs, and engineers - it makes switching even harder for organizations[16]. To go a step further, identify the tools your customers use before and after your product, and integrate those steps into your own workflow[16][17].
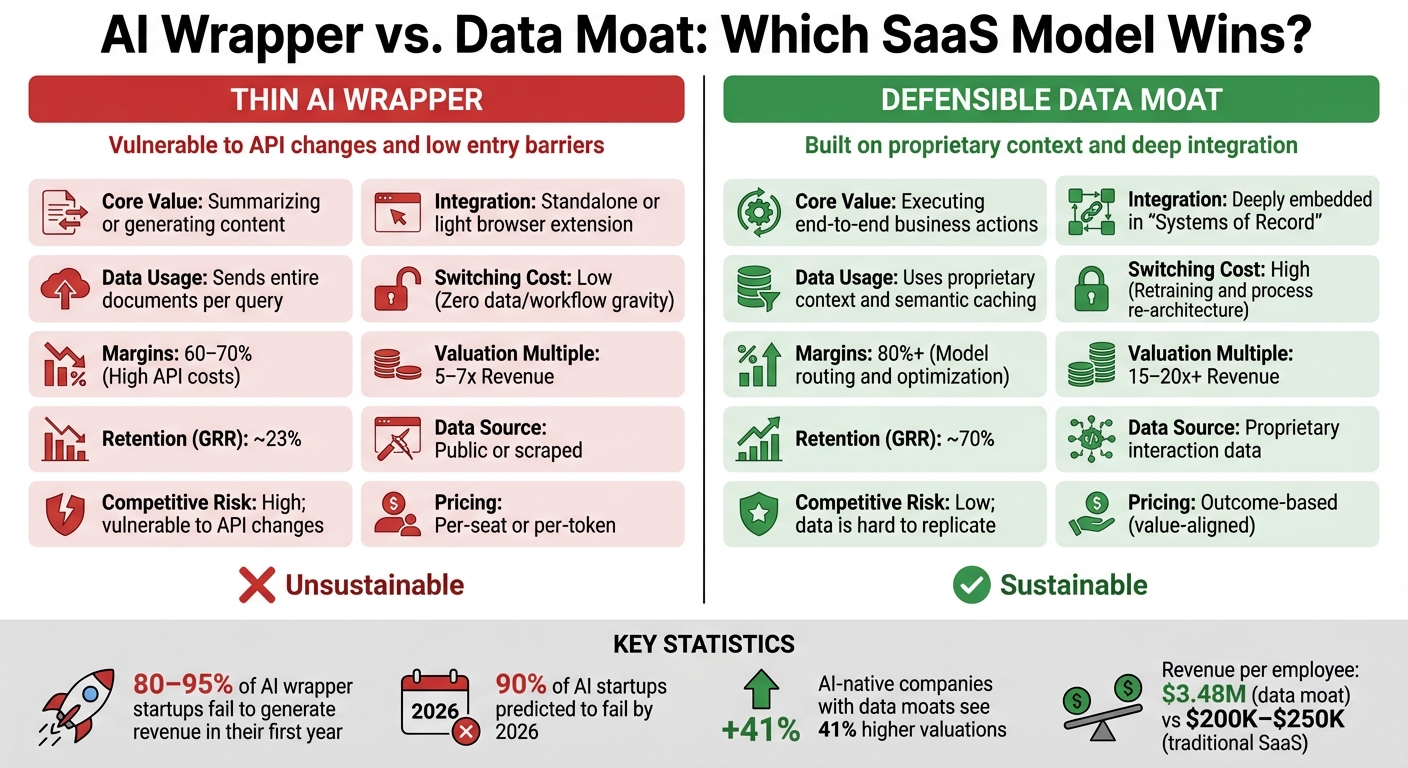
| Feature | AI Wrapper (Thin Layer) | AI-Native (Defensible Moat) |
|---|---|---|
| Core Value | Summarizing or generating content | Executing end-to-end business actions |
| Integration | Standalone or light browser extension | Deeply embedded in "Systems of Record" |
| Data Usage | Sends entire documents per query | Uses proprietary context and semantic caching |
| Switching Cost | Low (Zero data/workflow gravity) | High (Retraining and process re-architecture) |
| Margins | 60-70% (High API costs) | 80%+ (Model routing and optimization) |
Step-by-Step Framework to Future-Proof Your SaaS
AI Wrapper vs Data Moat: Key Differences in SaaS Business Models
You've seen the dangers of relying on thin AI wrappers and the advantages of building a strong data moat. This step-by-step guide will help you strengthen your competitive position and build resilience into your SaaS model.
Step 1: Audit Your AI Dependency
Start by evaluating how much your product depends on AI. Products generally fall into three categories:
- Tier 1: Fully dependent on third-party APIs.
- Tier 2: Use retrieval-augmented generation or fine-tune models with proprietary data.
- Tier 3: Develop custom models from the ground up [22].
To test your product’s durability, try replacing a third-party API with an open-source alternative. If this strips away your product’s unique value, it’s a red flag. Dive deeper by reviewing your production dashboards to analyze how your model handles edge cases and latency issues. Keep in mind, about 95% of generative AI pilots are currently failing [22].
Also, check if your team is using solid benchmarks like precision, recall, and F1 scores, rather than relying on anecdotal feedback. Finally, ensure that AI expertise isn’t concentrated in just one or two individuals - document everything thoroughly to avoid bottlenecks [22].
Step 2: Acquire Custom Data Sources
Once you’ve mapped out your vulnerabilities, the next step is to secure exclusive data assets. Focus on collecting behavioral data - how users interact with your product, what they accept or reject, and how they correct mistakes. This type of data, often called "data exhaust", is deeply tied to your product and nearly impossible for competitors to duplicate.
For example, Cursor tracks over a billion lines of code daily, using user feedback on code suggestions to build a model that outperforms generic language models [19]. To speed up your data acquisition, you could use specialized tools like AgileGrowthLabs.com to gather SaaS-specific data or partner with industries like manufacturing or biotech to tap into untapped, unstructured data [17].
The goal is to create a data flywheel - a system where more customer usage generates more proprietary data, which in turn improves your product [16].
Step 3: Build Continuous Feedback Loops
A strong data moat relies on feedback to refine and improve your AI over time. Create a dual-loop system:
- A short loop for real-time decision-making.
- A long loop for periodic model updates using accumulated feedback [21].
This approach turns every user interaction into a competitive advantage. Track implicit signals like user selection patterns, task completion times, and even negative signals (e.g., irrelevant outputs).
Take Harvey AI, for instance. By embedding 20% of its workforce as lawyers to validate AI outputs, it built a human-in-the-loop system that helped it achieve a $5 billion valuation and $100 million yearly revenue by November 2025 [19]. Similarly, Copy.ai used feedback from 16 million users to drive 480% revenue growth in 2024 [19].
"If you implement the short loop effectively, your periodic training runs will become more effective because the quality and precision of your feedback will improve if the agent improves in the short loop."
- Vikram Sreekanti and Joseph E. Gonzalez, The AI Frontier [21]
Also, design systems that remember user preferences and interactions across sessions. This builds a personalized experience that’s hard for competitors to replicate [19].
Step 4: Compare Thin Wrapper Risks vs. Data Moat Benefits
Before committing to building a data moat, weigh the risks of relying on thin AI wrappers against the benefits of proprietary data solutions. The table below highlights key differences:
| Feature | Thin AI Wrapper | Defensible Data Moat |
|---|---|---|
| Valuation Multiple | 5-7x Revenue [17] | 15-20x+ Revenue [17] |
| Switching Costs | Low; users can go to ChatGPT [5] | High; embedded in workflows [16] |
| Retention (GRR) | ~23% [23] | ~70% [23] |
| Data Source | Public or scraped [17] | Proprietary interaction data [18] |
| Competitive Risk | High; vulnerable to API changes [5] | Low; data is hard to replicate [22] |
| Pricing | Per-seat or per-token | Outcome-based (value-aligned) [9] |
AI-native startups with robust data moats often see valuation premiums of up to 41% compared to non-AI companies [23]. By the end of 2025, the AI sector accounted for $202.3 billion - almost 50% of global startup funding [23]. Companies with strong data moats also report revenue per employee metrics as high as $3.48 million, far exceeding traditional SaaS norms [23].
Conclusion: Future-Proofing Your SaaS with AI and Data
The SaaS landscape is evolving rapidly, and relying on superficial AI wrappers is no longer a viable strategy. If your product can be replicated with just an API key, you're essentially operating on borrowed time. Providers like OpenAI, Google, and Anthropic are already integrating these wrapper features directly into their platforms. The result? Low-cost AI wrappers are struggling, with a Gross Revenue Retention (GRR) of just 23%, compared to the 70% GRR achieved by specialized AI tools that leverage defensible data moats [23].
To stay competitive, it's time to pivot. Instead of focusing on systems of record, aim to build systems of action - AI that doesn’t just generate content but executes complex, multi-step workflows in critical operations. By capturing "data exhaust" - the valuable, structured context and user feedback generated during interactions - you can create a moat that competitors can’t scrape or replicate [20].
AI-native companies are already reaping the rewards, with valuations up to 41% higher than traditional software firms. Top performers are seeing revenue per employee soar to $3.48 million, far outpacing the $200,000-$250,000 range typical of traditional SaaS [23]. But speed alone won’t cut it; sustained momentum and defensible competitive barriers are what will set you apart [23].
Focus your efforts on industries where general-purpose AI models fall short, particularly in areas requiring deep contextual understanding or strict compliance. Building compliance infrastructure - such as tamper-evident audit trails for regulations like HIPAA, SOX, or GDPR - can create a 2-3 year head start that generic AI tools can’t easily overcome [4].
The decision is clear: evolve into a defensible system of action, or risk becoming a commodity. By leveraging proprietary data and locking in workflows, you can secure long-term value and resilience. Start by auditing your AI dependencies, acquiring unique data sources, and creating continuous feedback loops. Shift your focus from merely selling software to delivering actionable outcomes. The market has already set the bar: survival belongs to companies that own proprietary data and execute autonomous workflows. Make sure you’re one of them.
FAQs
How can I tell if my SaaS is just an AI wrapper?
If you're wondering whether your SaaS product is just an AI wrapper, take a closer look at its foundation. Does it depend solely on third-party AI models without adding any unique value, like exclusive data sets or specialized workflows? If your product’s core features can be easily duplicated by mimicking prompts or workflows and lacks meaningful integration or distinctiveness, it might fall into the "thin wrapper" category. Products like this often face challenges staying competitive over time.
What proprietary data should I collect to build a real data moat?
To establish a solid data advantage, prioritize gathering proprietary data that’s distinct, detailed, and difficult for competitors to duplicate. This might include data from user interactions, custom workflows tailored to your customers, or insights specific to particular industries, such as legal or healthcare sectors.
Additionally, consider building data flywheels - a system where your unique data enhances AI models, which in turn improves the user experience. This creates a self-reinforcing cycle that steadily boosts your product’s value over time, giving you a lasting edge in the market.
What’s the fastest way to add workflow lock-in without rebuilding my product?
The fastest way to ensure workflow lock-in is by weaving AI-native workflows directly into the fabric of your platform. This approach ties your product closely to your customers' essential operations, raising the barrier for switching to competitors. To solidify this even more, focus on creating proprietary data moats and establishing strategic partnerships. These moves not only boost your product's resilience but also deepen customer dependency - all without needing to reinvent your entire offering.
Related Blog Posts
- How AI Impacts SaaS Profit Margins
- I analyzed 50+ SaaS exits from the last 6 months. Companies with AI automation sold for 3.2x higher multiples. Here's the exact playbook
- Why Being “Just a SaaS Company” Isn’t Enough Anymore - Elevate to AI-Enabled Value
- Why AI SaaS Valuations Are 25.8x Revenue (And Why Your SaaS Might Be Worth More Than You Think)